Policy Enforcement
- Customizable rules block personal and subjective financial advice
- Adaptable content moderation across different use cases
- Configurable data scrubbing and privacy controls
Enterprise-grade compliance layer for financial AI.
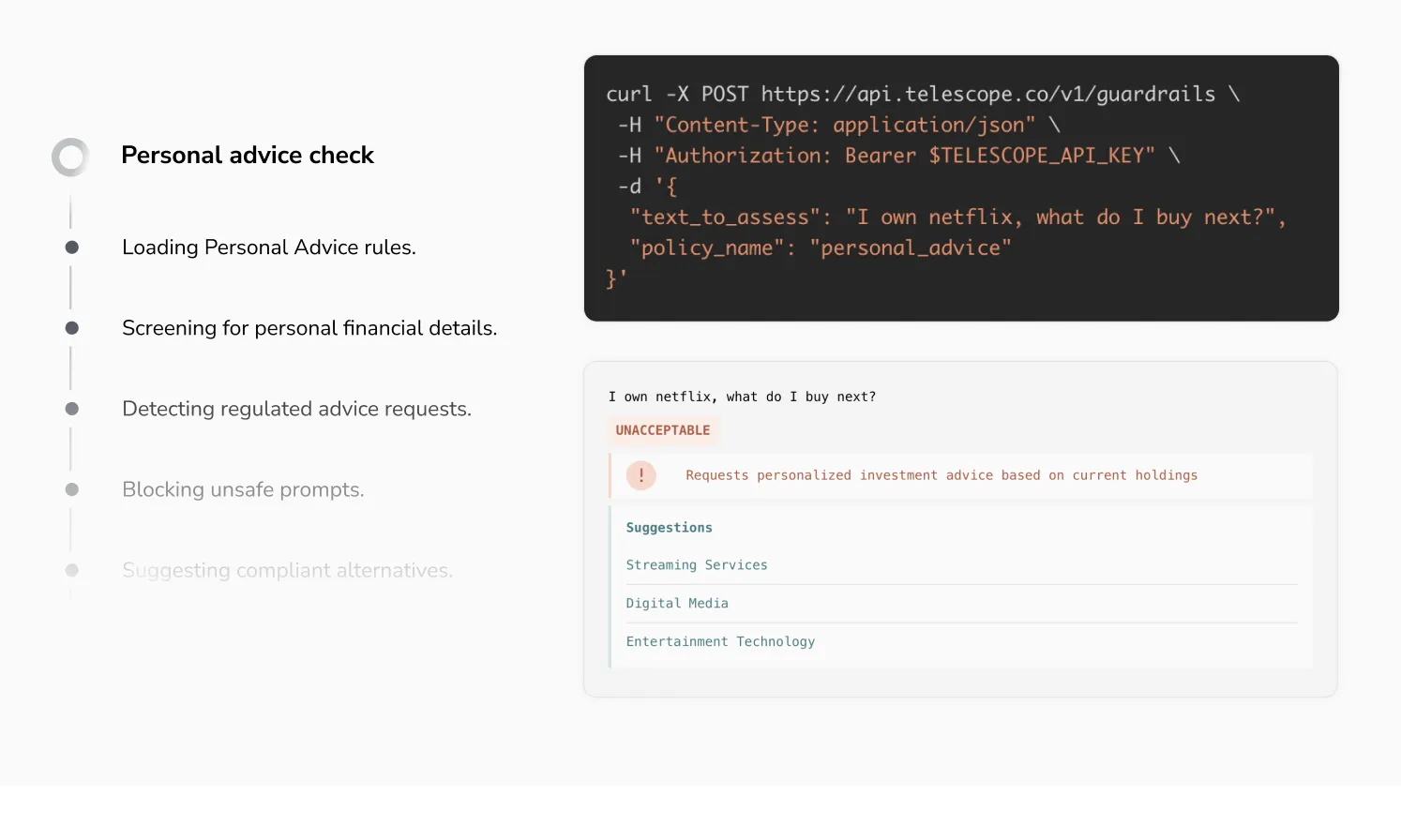
Blocks personal recommendations, subjective claims, and disallowed topics across every prompt, channel, and language.
Detects sensitive data in-flight, proactively raising warnings and redacting according to your policies.
Proactive monitoring of edge cases or concerning activity with human oversight and the ability to refine policies in real-time.
Discover how Guardrails underpins all products at Telescope.
Minimize risk, scrub personal information, and keep advice-free, compliant responses across every workflow





Our AI Safety & Ethics Policy establishes rigorous standards for responsible AI in financial services, covering data governance, monitoring, and escalation playbooks.
The living framework evolves as regulations shift, helping compliance teams validate workflows long before deployment.
Read the full AI Safety & Ethics Policy →
Every firm has unique workflows and compliance requirements. Let's discuss yours.
Request a demo →Get access to Guardrails on our dedicated platform environment, including custom deployments.
Request a demo →
Your data remains yours. DPAs across every frontier provider, optional self-hosting, and real-time logging guarantee transparency.
We collaborate with your compliance officers, providing production monitoring, detailed reporting, and configurable guardrails.
A dedicated research team continuously evaluates model behavior and performance, running proprietary benchmarks before deployment.
Every integration undergoes extensive testing so orchestration is stable, auditable, and ready for global financial workloads.
Tier 1 institutions rely on Telescope worldwide. Redundant models, comprehensive logging, and hardened infrastructure keep deployments online.
Custom deployments adapt to your workflows. Documentation, dedicated design support, and rapid prototyping accelerate time-to-value.


