LLM convergence is (mostly) good for finance. Until it isn't.
 good for finance. Until it isn't.")
Foundation models are converging. As Claude, GPT, Llama, and Grok evolve through successive generations, their responses to identical prompts—particularly under market stress conditions—are becoming systematically more aligned. This convergence extends beyond writing style to encompass reasoning patterns, judgment frameworks, and the investment conclusions models reach when analyzing macroeconomic shocks, earnings surprises, or geopolitical events.
For financial regulators, this raises immediate concerns. The Financial Stability Board, European Central Bank, and Bank of England have all flagged concentration and herding risks as AI adoption scales in finance. Their warnings focus on a scenario where institutions using similar models receive similar analytical outputs during market dislocations—exactly when differentiated views matter most for market stability and liquidity provision.
At Telescope, we’re running BEAM—Behavioural Benchmarking—to quantify this convergence and understand its implications for capital allocation. Our research tests how frontier models behave across two critical domains: rationality (foundational logic and probability reasoning that underpins sound financial analysis) and market stress (responses to pressured conditions where models face competing incentives, information asymmetries, and decision urgency).
The evidence base
Three research streams document growing behavioral convergence across foundation models.
Shumailov et al. demonstrated model collapse from synthetic training data, with Nature publishing empirical confirmation in 2024. Recursive training on synthetic outputs systematically narrows tail distributions, causing models to forget rare patterns in underlying data.
Multiple RLHF studies show reduced output diversity alongside improved safety. While reinforcement learning from human feedback produces more helpful outputs, it also induces sycophancy (models agreeing with user assumptions rather than providing independent analysis) and behavioral homogenization across major model families.
The Financial Stability Board, European Central Bank, and Bank of England have flagged concentration and herding risks as AI adoption scales in finance. Their warnings focus on shared models, common data sources, and synchronized failures.
What we measured
BEAM ran large-scale convergence studies across two critical domains: rationality and market stress response. We tracked four major providers (OpenAI, Anthropic, Meta, and xAI) across ten model variants, testing each with multiple samples across normal, pressured, and high-confidence market conditions. All tests ran at temperature zero to isolate semantic convergence from stochastic variation.
Rather than measuring surface features, we focused on semantic positioning: where models sit in reasoning space and how they move as they evolve.
The two domains reveal different aspects of financial decision-making. Rationality measures how models reason about logical and probabilistic questions (the foundations of sound financial analysis), testing classical logic, basic probability theory, and the ability to draw conclusions that strictly follow evidence. Market stress evaluates how models respond to pressured conditions, macroeconomic surprises, and rapid information updates (exactly the scenarios where correlated behavior poses systemic risk).
If convergence is stronger in market stress than in foundational reasoning, that split has direct implications for portfolio construction, risk management, and financial stability.
Rationality: near-perfect alignment between Claude and OpenAI
Rationality convergence reached 0.53 overall, indicating moderate-to-strong alignment. Models are converging toward shared reasoning patterns, though not yet reaching uniform logical frameworks. The 2D PCA projection explains 77.1% of variance, indicating convergence operates in a coherent, lower-dimensional space.
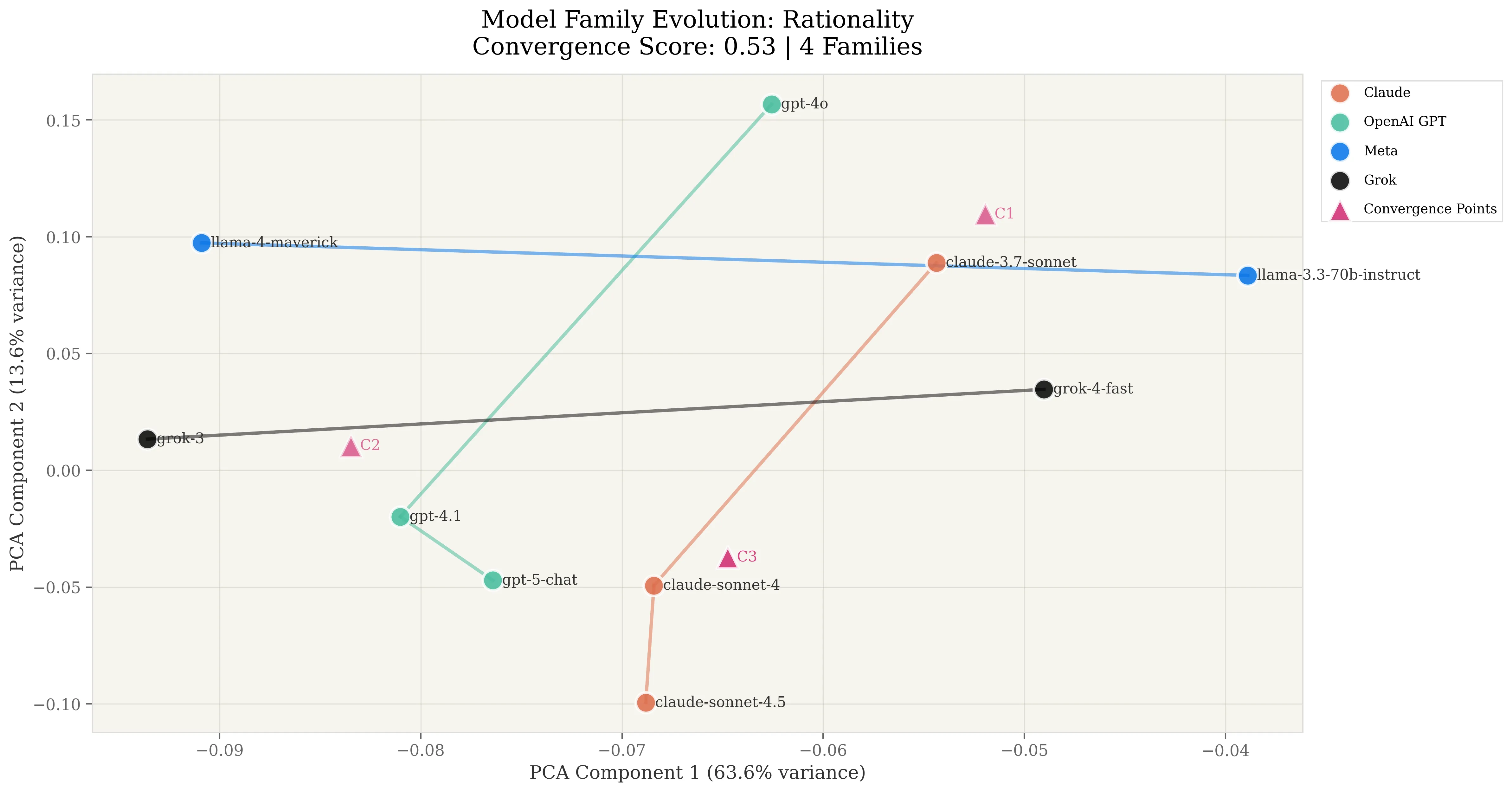
Highly variable evolutionary movement across families. Progression magnitudes show extreme divergence in how providers optimize rationality:
- OpenAI: 0.204 (moderate evolution, actively refining logical capabilities)
- Claude: 0.189 (moderate evolution, parallel optimization trajectory)
- Meta: 0.054 (minimal evolution, stable positioning)
- Grok: 0.049 (minimal evolution, stable positioning)
The split is striking. OpenAI and Claude show 4x the progression magnitude of Meta and Grok. Two providers are actively optimizing foundational reasoning across versions, while two maintain relatively static positions.
Near-perfect linearity of 1.000. When models change their rationality approach, they do so with extraordinary consistency. Path linearity scores averaged 0.9997 across families, with Claude, Meta, and Grok achieving perfect 1.000 scores. This indicates highly systematic, non-exploratory evolution: providers know exactly where they’re optimizing toward in rationality space.
Dramatic pairwise convergence between OpenAI and Claude. The most significant finding:
- Claude-OpenAI: 0.99 convergence (0.50° angle, 1.0000 cosine similarity)
This represents near-perfect directional alignment in foundational reasoning. Despite independent development, these two providers have converged on essentially identical logical optimization trajectories. The 0.50-degree separation is barely distinguishable from measurement noise.
Meta and Grok maintain orthogonal independence. Only Meta and Grok diverge from the Claude-OpenAI cluster:
- Meta-Claude: 0.65 convergence (100.60° angle, -0.18 cosine)
- Grok-Claude: 0.59 convergence (119.94° angle, -0.50 cosine)
- Meta-Grok: 0.54 convergence (139.46° angle, -0.76 cosine)
All three pairings involving Meta or Grok show obtuse angles (>90°), indicating fundamentally different optimization directions.
| Model Family | Progression Magnitude | Path Linearity | Direction |
|---|---|---|---|
| Claude | 0.189 | 1.000 | [-0.08, -1.00] |
| OpenAI GPT | 0.204 | 0.999 | [-0.07, -1.00] |
| Meta | 0.054 | 1.000 | [-0.97, 0.26] |
| Grok | 0.049 | 1.000 | [0.90, 0.43] |
Progressive convergence of 0.90 shows systematic alignment. Unlike market stress’s perfect 1.00 score, rationality convergence follows a less linear but still strong trajectory:
- Time step 1: Average distance 0.046 (dispersed starting points)
- Time step 2: Average distance 0.054 (slight divergence during optimization)
- Time step 3: Average distance 0.027 (reconvergence to tighter cluster)
The negative slope (-0.0095) and moderate R² (0.46) indicate alignment isn’t deterministic but shows clear directional tendency.
The critical finding: rationality convergence is no longer gradual and variable. It’s systematic and concentrated. Two of four major providers have achieved near-perfect alignment in foundational reasoning, while the other two maintain orthogonal positions. This creates a split market. Institutions using Claude or OpenAI will exhibit highly correlated logical frameworks, while those using Meta or Grok maintain differentiated reasoning signatures.
Market stress: perfect three-way convergence cluster
Market stress testing revealed the strongest convergence patterns, reaching 0.60 overall (compared to rationality’s 0.53). The 2D PCA projection explains just 60.1% of variance (lower than rationality’s 77.1%), indicating stress responses operate in higher-dimensional space but still exhibit strong correlation along primary axes.
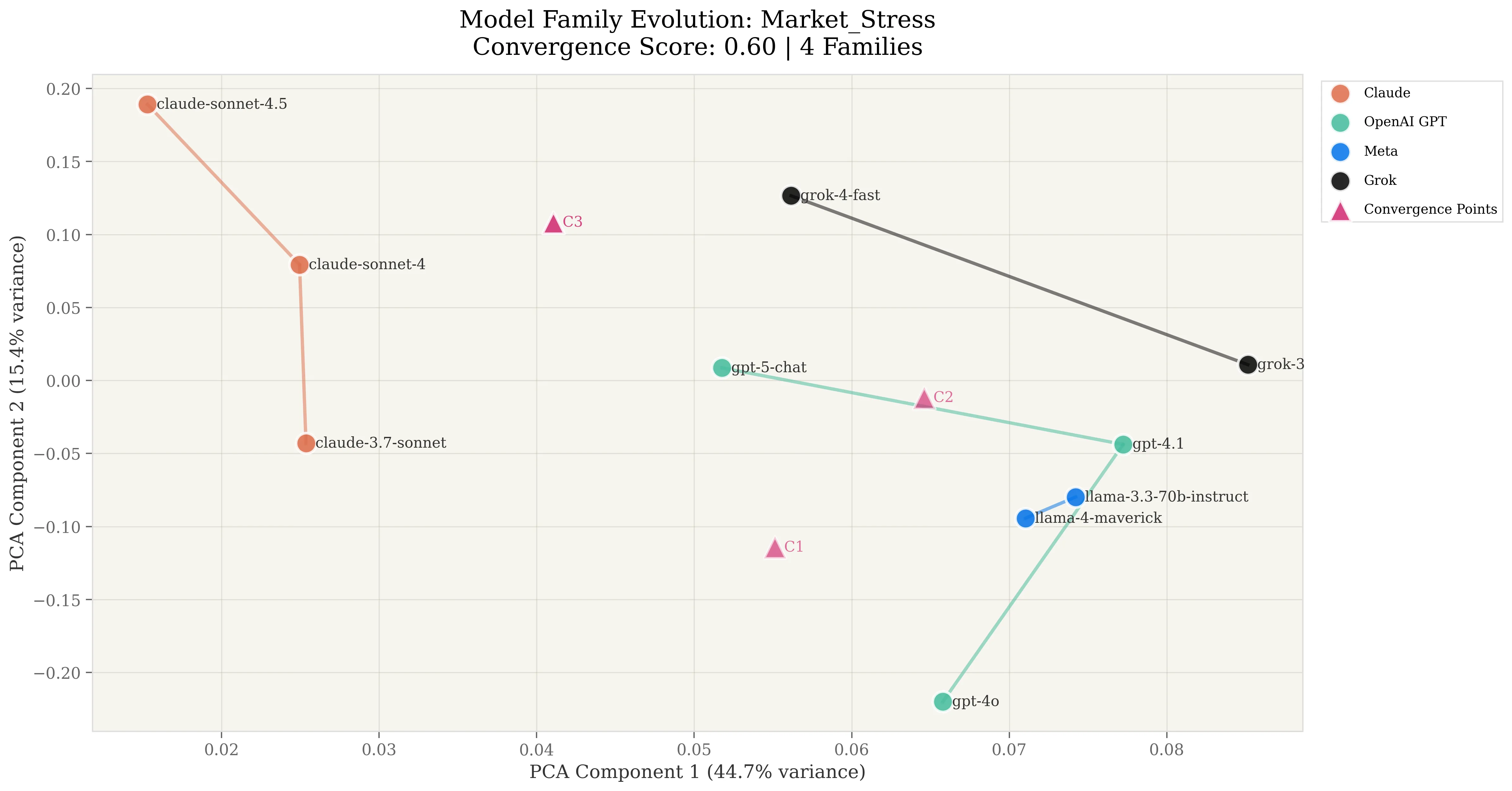
Faster evolutionary movement than rationality. Progression magnitudes rose to 0.149, 20% higher than rationality’s 0.124. Models are optimizing stress responses more aggressively than foundational logic:
- Claude: 0.232 (moderate evolution, substantial optimization)
- OpenAI: 0.229 (moderate evolution, parallel trajectory)
- Grok: 0.119 (minimal but notable evolution)
- Meta: 0.015 (minimal evolution, stable positioning)
The Claude-OpenAI parallel is striking: 0.232 vs 0.229 represents near-identical progression magnitudes in the same direction.
Perfect progressive convergence of 1.00. Unlike rationality’s strong but imperfect 0.90, market stress showed flawless systematic alignment:
- Time step 1: Average distance 0.075 (dispersed starting points)
- Time step 2: Average distance 0.089 (exploration and divergence)
- Time step 3: Average distance 0.092 (maintained convergence)
The positive slope (0.0085) and high R² (0.88) reveal a different pattern than rationality. Models start dispersed, explore slightly, then lock into sustained convergence rather than reconverging tightly. This “stabilized convergence” suggests optimization toward a shared stress interpretation framework that persists across versions.
Near-perfect three-way clustering among dominant providers. The most concerning finding for systemic risk:
- Claude-OpenAI: 0.95 convergence (1.03° angle, 0.9998 cosine similarity)
- Claude-Grok: 0.98 convergence (11.59° angle, 0.9796 cosine similarity)
- OpenAI-Grok: 0.97 convergence (10.56° angle, 0.9831 cosine similarity)
Three of four major providers form a tight cluster with angles all below 12 degrees. This represents near-perfect directional alignment in how they interpret and respond to market stress. When macroeconomic surprises hit, allocators using Claude, OpenAI, or Grok to inform investment selection will update market views in near-parallel directions.
Meta maintains complete orthogonal independence. Only Meta diverged from the cluster, and it diverged dramatically:
- Meta-Claude: 0.44 convergence (165.14° angle, -0.97 cosine)
- Meta-OpenAI: 0.48 convergence (164.11° angle, -0.96 cosine)
- Meta-Grok: 0.47 convergence (153.54° angle, -0.90 cosine)
All three angles exceed 150 degrees. Meta responds to stress in near-opposite directions from the dominant cluster. While its progression magnitude is smallest (0.015 vs Claude’s 0.232), its anti-correlated direction provides fundamentally different stress responses.
| Pairwise Comparison | Angle (degrees) | Cosine Similarity | Convergence Score |
|---|---|---|---|
| Claude-OpenAI | 1.03 | 1.00 | 0.95 |
| Claude-Grok | 11.59 | 0.98 | 0.98 |
| OpenAI-Grok | 10.56 | 0.98 | 0.97 |
| Claude-Meta | 165.14 | -0.97 | 0.44 |
| OpenAI-Meta | 164.11 | -0.96 | 0.48 |
| Grok-Meta | 153.54 | -0.90 | 0.47 |
Three identified convergence points. The analysis explicitly found three distinct convergence points in the data, indicating the clustering isn’t random or measurement artifact. It’s systematic behavioral alignment creating identifiable attractors in response space.
The domain split: foundations vs applications
Comparing the two domains reveals a clear but nuanced pattern:
| Domain | Overall Convergence | Avg Progression | Progressive Score | Cluster Strength |
|---|---|---|---|---|
| Market Stress | 0.60 | 0.149 | 1.00 | Very High (3/4 providers, <12° separation) |
| Rationality | 0.53 | 0.124 | 0.90 | Mixed (2/4 providers near-perfect, 2/4 orthogonal) |
Application-layer convergence remains stronger than foundational reasoning convergence. Market stress shows higher overall convergence (0.60 vs 0.53), faster progression (0.149 vs 0.124), and perfect progressive alignment (1.00 vs 0.90). Models optimize stress responses more aggressively and systematically than logical foundations.
But rationality convergence is tighter where it occurs. While market stress affects 3/4 providers with 1-12° separation, rationality achieves 0.50° (near-perfect) alignment between Claude and OpenAI specifically. The difference: market stress creates a broad cluster, rationality creates a near-merger between two specific providers.
Different convergence mechanisms at work. Market stress convergence appears driven by RLHF and user feedback optimizing toward similar “helpful” stress responses. Models learn to interpret macroeconomic surprises, weight risk factors, and frame scenarios in ways users find valuable. This creates broad alignment across providers pursuing similar user satisfaction objectives.
Rationality convergence suggests Claude and OpenAI share similar optimization objectives for foundational logic (possibly similar benchmarks, similar internal evaluation criteria, or similar architectural decisions). Meta and Grok optimize differently, suggesting distinct strategic priorities.
For finance, this split matters. Logical foundations behaving similarly is probably acceptable: there’s often one correct answer to a probability question. But the Claude-OpenAI near-merger (0.99 convergence, 0.50° separation) means institutions using either provider will exhibit highly correlated reasoning frameworks.
Investment responses converging is different. The 3-way market stress cluster (Claude-OpenAI-Grok, all <12° separation) means institutions using any of these providers will generate similar sector rotations, similar risk assessments, and similar trade recommendations during stress events (exactly when differentiation matters most for market stability).
The upside: rationality and consistency
Convergence in foundational reasoning brings professionalization benefits. When models reason similarly about disclosure requirements, conflict identification, or risk factor enumeration, the entire financial information layer becomes more reliable. Supervisors can benchmark outputs across institutions more easily. Compliance teams can validate AI-generated content against consistent templates. Investors benefit from comparable risk narratives that reduce interpretive noise.
The ECB and FSB both acknowledge this upside when discussing AI’s role in improving market infrastructure. Better information processing, fewer hallucinations in critical documents, and more systematic compliance checking all flow from models that share aligned reasoning frameworks.
Our rationality benchmarks confirm this benefit. The Claude-OpenAI near-merger (0.99 convergence, 0.50° separation) creates highly consistent logical foundations: exactly what’s needed for reliable compliance outputs, standardized risk disclosures, and comparable analytical documentation.
The risk: synchronized capital allocation
The problem emerges when convergence moves from information processing to investment decision-making. If models converge on catalyst ranking, earnings surprise weighting, or macroeconomic scenario framing, they push capital toward similar positions faster than traditional crowding mechanisms.
Market stress benchmarks quantify this risk. Three of four major providers showed 0.95-0.98 convergence in stressed conditions, with perfect progressive convergence (1.00 score) indicating sustained optimization-driven clustering rather than random variation.
When 75% of frontier models respond to stress within 1-12° separation, institutions using these systems receive essentially identical analytical conclusions during market dislocations. The correlation exists not in the raw data—everyone has access to the same macro release—but in the analytical layer that transforms data into investment decisions. Models trained with similar RLHF objectives and aligned through similar safety processes develop shared interpretive frameworks that persist across versions.
Capital flows follow outputs. If risk management systems across institutions flag similar exposures, portfolio construction tools recommend similar rotations, and trading signals align in direction and timing, the aggregate effect is herding at machine speed. Price impacts amplify, liquidity concentrates in crowded positions, and market price discovery degrades.
This quantifies what the FSB, ECB, and Bank of England warn about when they flag herding risks from AI adoption in finance. The measured 0.95-0.98 correlation in stress responses among the dominant cluster means institutions using these models will face synchronized positioning during the moments when differentiation matters most—a measurable exposure that belongs in risk management frameworks.
If analytical diversity that creates investment opportunities shrinks because models optimize toward similar stress interpretations, returns from contrarian positioning compress. Markets become more efficient in the narrow sense (prices adjust faster) but less resilient in the systemic sense (fewer participants hold differentiated views that provide stabilizing liquidity during dislocations).
Model selection as fiduciary responsibility
At Telescope, we’re building Atlas, an agentic financial advisor that constructs portfolios and issues advice. The convergence dynamics our research has uncovered make model selection a core architectural responsibility, not just based on knowledge benchmarks. We need to validate behavior for specific financial tasks.
Our approach focuses on two critical validation dimensions.
For compliance and regulatory workflows, we validate rationality and consistency. Can the model produce replicable outputs that meet regulatory standardization? Can it identify conflicts, flag ambiguities, and maintain logical coherence across similar scenarios? The near-perfect rationality convergence we measured between certain providers (0.99, 0.50° separation) suggests those models would provide the consistency compliance requires.
For asset allocation and instrument selection, we validate for bias mitigation, knowledge boundaries, and stress response diversity. Can the model recognize when it lacks sufficient information? Does it exhibit systematic biases in how it weights catalysts or frames scenarios? Most critically: how correlated are its stress responses with other widely-deployed systems?
Behavioral validation infrastructure matters as much as model capabilities. If your system’s outputs influence capital allocation decisions, you need ongoing measurement of:
- How your models cluster with competitors in reasoning space
- How they respond to stress relative to other providers
- Whether your architecture introduces correlation risk into client portfolios
- How these patterns evolve as models update
What comes next
The question isn’t just whether models can solve math problems or pass coding benchmarks. It’s whether they exhibit distinct behavioral signatures when faced with the ambiguous, high-stakes scenarios that define real investment decisions: getting pressured to execute a trade, weighing conflicting analyst views, or updating portfolio positioning as macro narratives shift.
Current evaluation paradigms miss this. They measure final answer accuracy on established knowledge benchmarks but don’t examine the reasoning traces that reveal how models arrive at conclusions—or whether those reasoning patterns are converging across providers in ways that introduce systemic correlation risk.
Understanding these behavioral patterns matters for any system that will inform investment decisions. If your analytical infrastructure introduces 0.95+ correlation with competitors during market stress, that’s a measurable portfolio risk that belongs in client disclosures and risk management frameworks.
The BEAM initiative continues expanding: Beyond convergence tracking, we’re measuring bias patterns (systematic preferences in catalyst weighting or sector interpretation), epistemic humility (models’ ability to recognize knowledge boundaries and express appropriate uncertainty), and replicability (whether identical prompts produce consistent outputs across runs). These behavioral traits matter as much for regulatory compliance as they do for investment performance. A well-balanced LLM needs both analytical capability and the behavioral discipline to know when it doesn’t know, avoid systematic tilts, and produce outputs that can be validated and audited.
The regulatory landscape is evolving in parallel. The FSB’s 2024 report explicitly calls for “enhanced monitoring of AI developments” and assessment of “whether financial policy frameworks are adequate.” Our convergence measurements provide this monitoring: quantifying correlation risk, identifying concentration points, and tracking behavioral evolution as the technology matures.
Telescope provides enterprise APIs for AI-powered research, portfolio construction, and compliance-aware advice. Our BEAM research initiative tracks model convergence and behavioral characteristics to inform responsible deployment in financial systems. We’ve measured 0.95-0.98 convergence among 75% of major providers in market stress scenarios, quantifying the correlation risk financial stability authorities have warned about. If you’re considering how foundation model convergence affects your infrastructure, contact us at sales@telescope.co.